Compania DeepMind a Google, celebra pentru anunturile legate de inteligenta artificiala, a prezentat un sistem care poate imagina un mediu 3D pornind de la o simpla fotografie bidimensionala. Cercetarea publicata in revista Science este un pas catre un fel de ”Sfant Graal” al computing-ului: soft-ul sa observe cu exactitate mediul inconjurator si sa imagineze lucruri noi, pornind de la foarte putine date, nu de la milioane de fotografii, ca in prezent.
”Lucrarea de acum ne duce cu un pas mai aproape de computerele care pot intelege diverse ipostaze la fel cum le intelegm noi oamenii si, foarte important, fara supraveghere umana explicita”, spune seful de proiect S. M. Ali Eslami.
Metoda, bazata pe retelele neurale avansate, este viabila doar pentru mediile virtuale, pentru ca mediul natural este prea greu de gestionat de catre algoritmii din prezent.
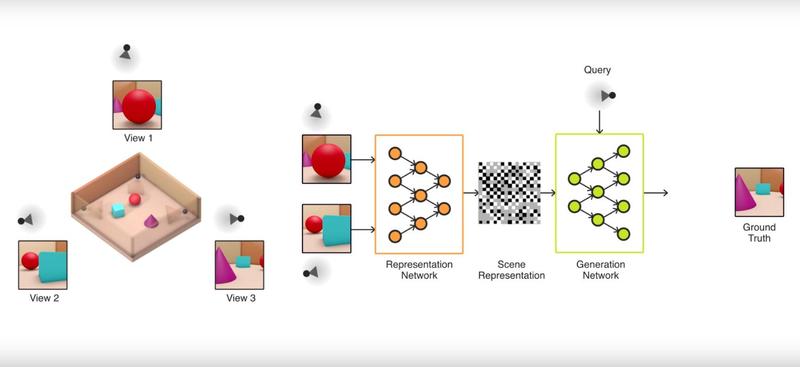
Sistemul de ”artificial vision” este numit Generative Query Network (GQN) si partea speciala la acest sistem este ca invata foarte mult pornind de la extrem de putine exemple si nu are nevoie de milioane de imagini de la care sa invete. De exemplu in experimentele descrise in lucrare nu a pornit de la mai mult de cinci fotografii si creaza un mediu 3D pornind de la observatii. fara a fi nevoie ca cineva sa eticheteze obiectele si fara indicatii despre perspectiva sau lumina.
”Pentru a antrena un computer sa recunoasca o scena furnizata de senzorii sai vizuali, cercetatorii folosesc, in mod normal, milioane de imagini etichetate cu mare greutate de catre oameni. Eslami si echipa au dezvoltat un sistem de tip artificial vision, numit Generative Query Network, care nu are nevoie de astfel de date etichetate. GQN foloseste imagini din diverse unghiuri si creeaza o descriere abstracta a scenei, invatand esentialul. Apoi, pe baza acestei reprezentari, reteaua estimeaza cum ar arata scena, dintr-un punct de vedere nou, arbitrar”, spun cercetatorii, in revista Science.
Modelul GQN este compus din doua parti, practic din doua retele neurale: una de reprezentare si una de generare. ”Reteaua de reprezentare ia observatiile agentului ca input si produce o reprezentare (un vector) care descrie scena implicita. Reteaua de generare prezice apoi (imagineaza) scena dintr-un punct de vedere neobservat in prealabil”.
Autorii studiului nu dau exemple de aplicatii comerciale, insa tehnologia ar putea fi utilizata pe viitor la sisteme de supraveghere, la masini autonome sau la roboti casnici.
Telul este sa se ajunga la situatia in care computerele sa recunoasca fara probleme cum sunt plasate obiectele, ce sunt, la ce distanta se afla unul de altul, si toate acestea fara sa fie nevoie ca oamenii sa introduca milioane de linii de date.